ADO.NET Optimizing DataReader Performance
Coming back to ADO.NET, I sometimes forget of different ways of accessing values from the SqlDataReader, cost of a type unboxing and which method is to use when. For example, here are different ways we can access values:
- using a typed accessor SqlDataReader.GetInt32(int columnOrdinal)
- geting a value directly with named column like this SqlDataReader[“columnName”] or with column ordinal SqlDataReader[0] and then casting it
- call SqlDataReader.GetOrdinal(“columnName”) to get column position and then combine the result and call the typed accessor method like SqlDataReader.GetInt32(SqlDataReader.GetOrdinal(“columnName”)).
For performance benefits using Typed Accessors like reader.GetInt32 or reader.GetDateTime is always faster since there is no type conversion or unboxing occurs. But these typed accessors only accept column ordinal or column position and most of the times you don’t want to hard code your column position since that could change at any time and break your application.
I wrote a series of tests that test each scenario in the context of:
- Getting one record 100000 times, that emulates retrieving of one row.
- Getting 20k records 1000 times, or simulating retrieving large amount of rows
The results are as follows:
Getting one row over 100k times:
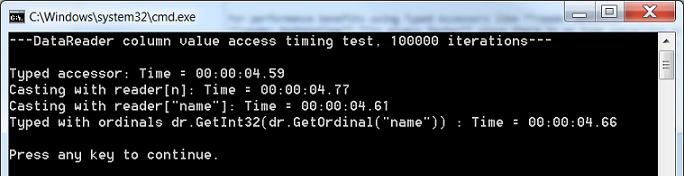
There is really no difference or any significant performance advantage when accessing one row. When you run the test multiple times numbers change slightly and there is no clear winner. So we can say if you are only getting one record you can use any one of those accessors and cast as you please.
Getting 20k records over 1000 times
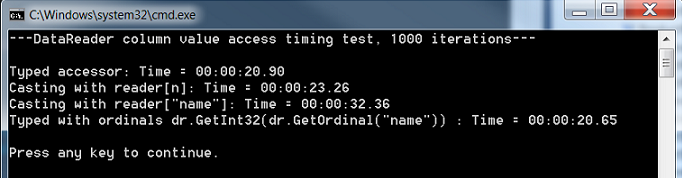
Typed accessor proves to be the fastest. Right behind is casting by using column orderinal accessor. Casting with column name is probably 30% slower than casting typed casting. And finally if we call reader.GetOrdinal once and cache the column position we get as fast performance as typed accessor alone.
Summary
If your query returns only one row or small amount of rows it doesn’t matter which method you use. It would only make sense if you have large number of rows and using reader.GetOrdinal to cache column number and then using typed accessors would yield the best performance.
If you want to see for yourself you can download the source code and run it against the AdventureWorks database.