Going Database Free Feels Great
A New, Fresh Look at Old and Boring
I get excited when playing with frameworks that are different and challenging to a widely-accepted view on the subject at hand. One of those commonly accepted notions is that in order to build a content management system (CMS), you need a web server and a database. One guy who challenged that notion is Tom Preston-Werner who, in his original article “Blogging Like a Hacker”, set out to fix his frustrations with existing systems. He wrote:
I was tired of complicated blogging engines like WordPress and Mephisto. I wanted to write great posts, not style a zillion template pages, moderate comments all day long, and constantly lag behind the latest software release.
He broke down the problem and realized that the core of the platform is your content, your layout, and the templating engine that will allow you to format and display your content. A simple, genius solution that he came up with is a static site generator, a project named Jekyll that will take your posts in the form of markdown files and run them through a generator that converts your layout and templates into a fully-generated static site. You can take that and host it anywhere you like because it’s just a simple site with static files.
Jekyll: A Perfect Fit
Markdown Format
I already love markdown format. I think it fits perfectly with the web. It allows you to craft simple web pages without HTML getting in your way, and it’s unified. There are now numerous editors that support markdown, so you get to choose the one you like rather than get stuck with what your CMS or blogging platform has to offer. In addition, your blog posts are physical text files that you can save in source control or back up in something like Dropbox. And if you ever decide to switch platforms, you can easily take and import those files to the new and shiny thing.
Simple HTML Layouts
You can create your own simple HTML files and drop Liquid template variables to display the content. Super simple and powerful.
Here is an example of a post page with template tags.
<div class="home entry">
<h1>{{ page.title }}</h1>
<span class="date">{{ page.date | date_to_long_string }}</span>
{{ content }} ...
</div>
The page tags are also custom, and you can define your own. It’s as flexible as you can imagine. Here is an example:
---
layout: post
title: "Going Database Free Feels Great"
tags: ["jekyll", "cms"]
---
The date comes from the file name. Jekyll uses filename convention to pull the post date, so your post has to start with a date, for example: 2013-09-21-myblogpost.html.md
You can also generate sitemap and feed files, as well as define your own URL structure, and much more.
Super cheap
Did I mention that it’s super cheap to host a static site because you don’t need that fancy web server and database? All you need is an Amazon S3 account, and it will cost you pennies every month to run your site. You can just as easily host your site on Github for free.
Unlimited traffic
How many times have you seen articles on Hacker News that, when you click on them, give you a nice 500-page error? That’s because their Wordpress on the shared hosting cannot handle all the traffic, and it just bogs down. Well, with static sites hosted in the cloud, you get unlimited traffic potential out of the box. It will serve almost any amount of traffic you can throw at it.
Secure as it can get, no need to maintain
The beauty of the static site is that it’s simple and doesn’t have any programming logic. You don’t need to download any patches or security updates-it’s all just static HTML file goodness. Feels like we are back in 1996, and it’s awesome!
Static Site + CDN = FAST!
Now to my favorite part. Being a performance freak, I have to admit that I decided to try it out because I knew that putting a CDN in front of the static site can make it really fast. I tried Amazon Cloud Front at first, but their speed was not very impressive. I was getting 600-700 ms response times, which is slower than the DiscountASP provider I was using before. I found MaxCDN, and they were just what I was looking for. I now see responses in the 50 ms or less range, and www.webpagetest.org reports 96/100 point results. It’s incredibly fast!! Here is a proof:
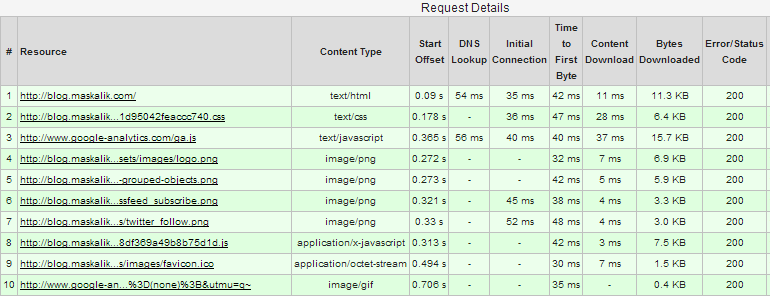
In addition, MaxCDN is doing a great job of zipping all of my content for me automatically.
Plugins
Jekyll has a big ecosystem, and there are a lot of plugins that are available. One in particular that I found very useful is jekyll-assets. It’s very easy to set up, and it will take care of your minification, combining of css/js files, coffee script conversion, and cache busting, etc.
What about comments
Aren’t comments something that your platform needs? How do you go about that? Well, that’s simple—you can install a 3rd party solution like Disqus, or you can roll your own with Javascript and Windows Azure mobile services. In this day and age, anything that requires a database can be sprinkled on the page with Javascript, and 3rd parties will host your data very cheaply.
Extras
I’ve created a simple publishing application that you can run from the root of your Jekyll site. It will take contents of the site folder, figure out the differences between local copy and Amazon S3, and publish those differences to Amazon S3. Finally, it will purge cache in MaxCDN.
Summary
By keeping things simple and ignoring prior biases, we gain incredible benefits that solve problems perfectly. I’m excited and looking forward to blogging on my new, shiny, statically-generated site.